
为什么是Hive
Hive由Facebook实现并开源,是建立在Hadoop之上的数据仓库解决方案。
- 学习门槛低:
会sql即可 - 可扩展性好:
可自由扩展集群规模,且支持UDF - 容错性不错:
一个节点出问题,继续执行。 虽然Impala、Spark SQL、Drill、Hawq 和Presto 一直在运行性能、并发量和吞吐量上击败Hive,但是Hive 仍然是最流行的(至少根据DB-Engines 的标准)。原因有3个:
- Hive 是Hadoop 的默认SQL 选项,每个版本都支持。而其他的要求特定的供应商和合适的用户;
- Hive 已经在减少和其他引擎的性能差距。大多数Hive 的替代者在2012年推出,分析师等待Hive 查询的完成等到要自杀。然而当Impala、Spark、Drill 等大步发展的时候,Hive只是一直跟着,慢慢改进。现在,虽然Hive 不是最快的选择,但是它比五年前要好得多;
- 虽然前沿的速度很酷,但是大多数机构都知道世界并没有尽头。 关键是稳定和容错(继承了mapreduce)。
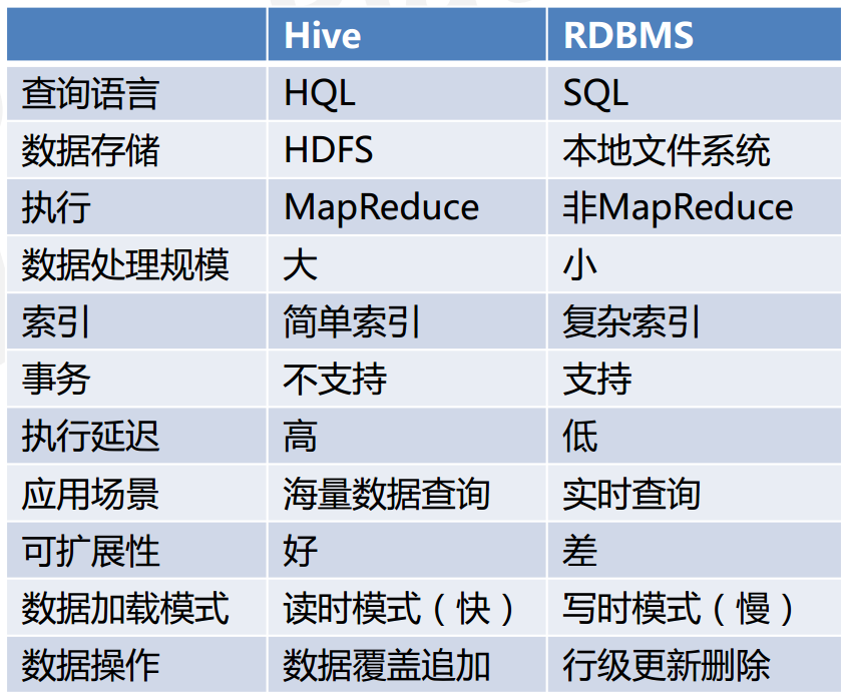
Hive与关系型数据库的对比:
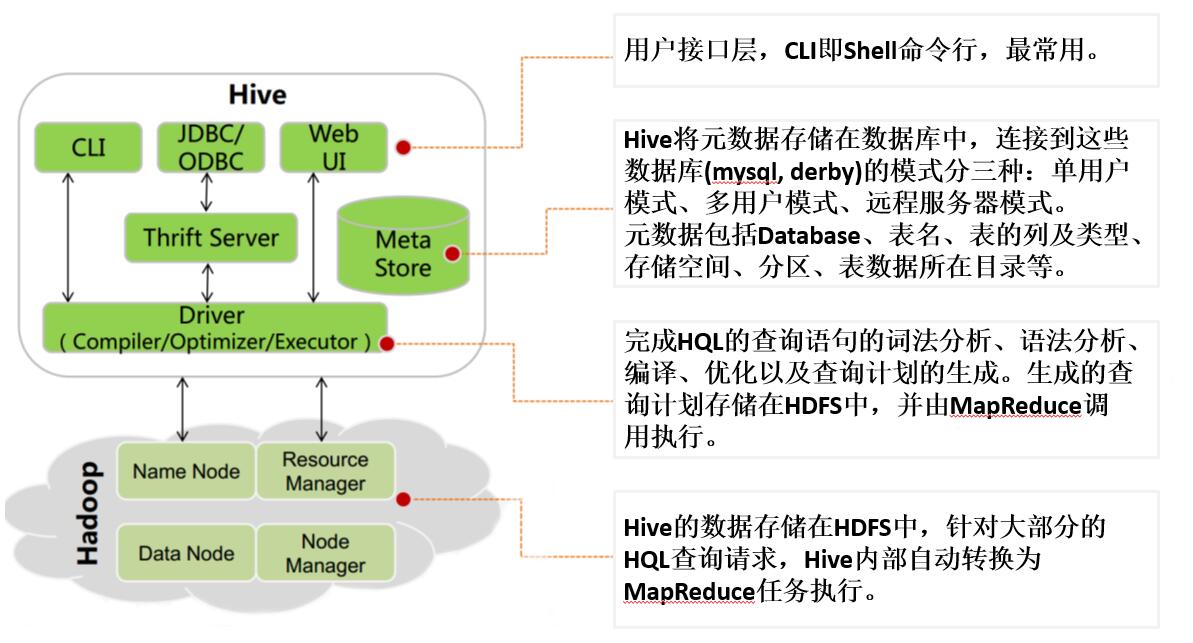
Hive架构
Hive数据模型
内部表
与传统数据中的表类似,在Hive中每一个
Table都有对应的目录存取其数据。当删
除表时,其元数据和表中的数据都会被删除。
例句:create table test_inner_table (key string)外部表
与内部表不同,外部表只是与外部数据建立一个链接。删除外部表时,只会删除该
外部表的元数据,外部数据不会删除。
例句:create external table test_external_table (key string)分区表
在Hive中表的一个Partition对应表下的一个子目
录,所有Partition的数据都存储在对应子目录中。
例句:create table test_partition_table (key string) partitioned by (ds string)分桶表
选择表的某列通过Hash算法将表横向切分成不同的文件存储。
例句:create table test_bucket_table (key string) clustered by (key) into 20 buckets视图
与传统数据库视图类似,只读,基于基本表创建。
例句:create view test_view as select * from test_inner_table
存储格式
| 存储格式 | 存储方式 | 优缺点 | 实际应用推荐 |
|---|---|---|---|
| Textfile | 行存储 | 加载速度最快,但占磁盘,压缩后不支持并行 | 底层数据 |
| sequencefile | 行存储 | 压缩率低,查询速度一般。 | 中间层数据 |
| rcfile | 按行分块,每块按列存储 | 压缩率最高,查询速度最快,数据加载最慢。 | 冷数据 |
| orcfile | 按行分块,每块按列存储 | rcfile的改良版本 | 冷数据 |
